Introduction
It started with a simple desire to obtain a CVE at a time when bug bounties were closing. I arbitrarily downloaded an open-source project, instructed Claude-Code to read its Security.md and analyze/classify existing CVEs, and naturally received several vulnerability candidates similar to the existing CVEs.
However, during the implementation and verification process, I confirmed that they were not vulnerabilities for various reasons. After wasting tokens so meaninglessly, I concluded that there were limitations to finding vulnerabilities through simple static source code analysis. This led me to think about creating an open-source vulnerability analysis flow and using Local LLMs and MCP tools if necessary.
Coincidentally, among the open-source candidates I wanted to find vulnerabilities in, there was an AI flow open-source project called Flowise. Initially, I thought a project like ‘Finding Flowise Vulnerabilities using Flowise’ would be interesting, so I proceeded with it. However, due to the performance limitations of Local LLMs and the difficulty of debugging, I ended up pursuing additional learning and exploring different directions.
1) Test1 : Flowise & Local LLM(Qwen3:14b)
Settings
- Flowise In docker container
- Ollama
- Local llm model Qwen3:14b
- almost opensource llm model do not support tool calling or standard of MCP tool calling
- While setting it up, I realized how amazing commercial LLM services truly are.
- Burp Suite MCP
- MCP bridge to Flowise container (AI handmade; the given proxy and Burp Suite must follow a defined data format, but it didn’t match Qwen’s tool calling format, so I created a proxy)
Flowise
- Custom MCP node ⇒ Tools of the Tool agent Node
- The Custom MCP node calls Burp MCP through a self-made bridge.
- Ollama Node ⇒ Tool calling chat model of the Tool agent Node
- Qwen3:14b, set with a Context Window of 16k tokens.
- Buffer Memory ⇒ Memory of the Tool agent Node
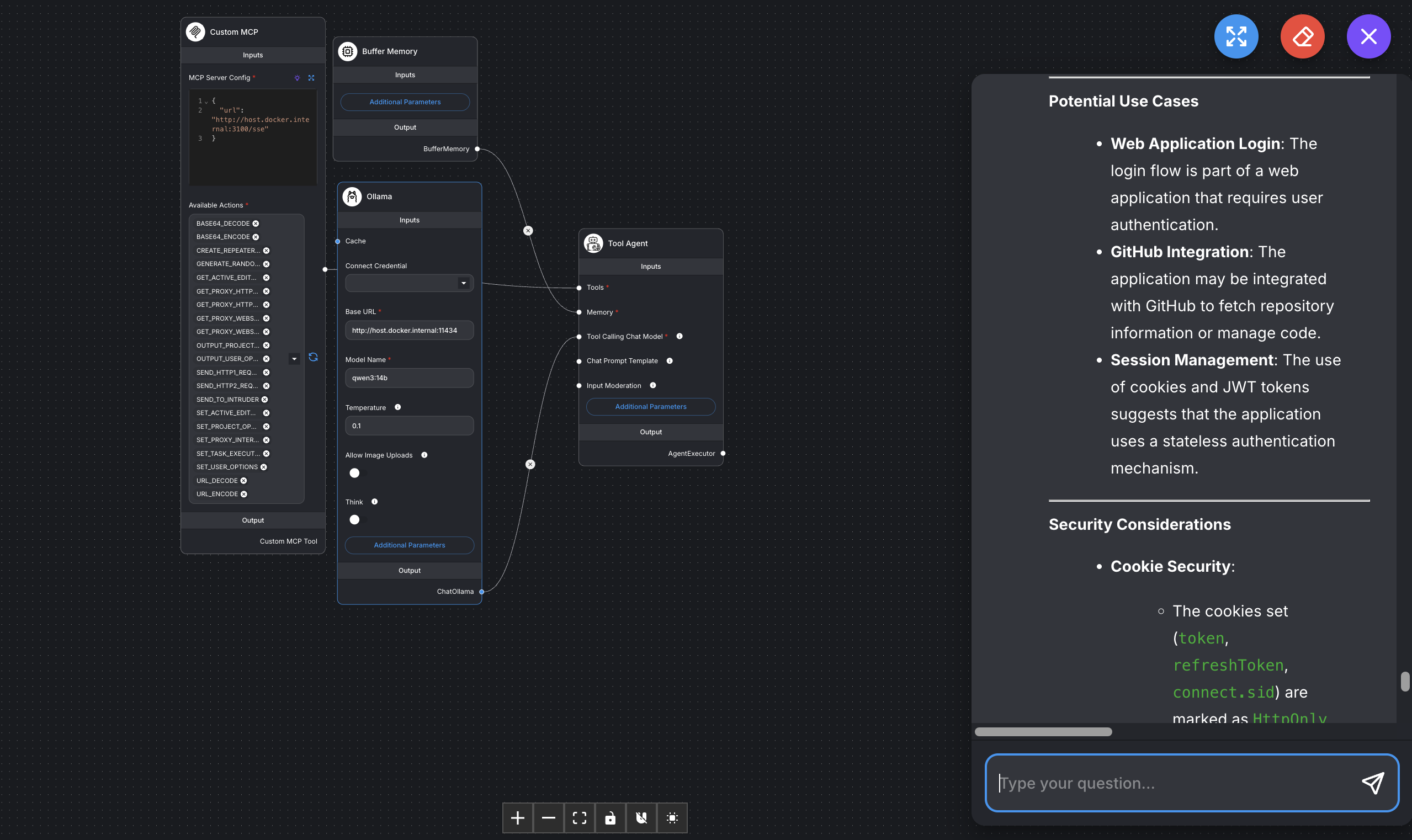
Test1 Challenging
-
Local LLM Performance
- Difficulty understanding context due to insufficient token count.
- Unlike commercial models, MCP tool usage is not fluent; separate models exist that support tool calling.
- Meanwhile, I felt my MacBook, which rarely got hot, heating up.
-
Lack of LLM Service Design Capability
- Started with the need to reduce commercial LLM usage, but ultimately lacked overall learning on how to handle agents, which LLM model is suitable, etc.
- Realized it was very difficult to harness even the MCP tool aspects in an unprepared state.
- Had no idea how to proceed with harnessing in Ollama.
⇒ Realized the need to set smaller goals and proceed. ⇒ It’s necessary to gradually establish a methodology for vulnerability analysis itself… and a lot of thought will be needed to run that part with local models. For Test2, I decided to perform some simpler documentation tasks to get familiar with AI while studying it.
2) Test2 : Change LLM Model(gemma4:e4b) & Specify the purpose to use Local LLM
Test2 Project Goal : Create AI Vulnerability Security Review Items
Previously, I tried creating AI security review items with NotebookLM, but retrieving supporting clauses was unstable. I judged that relying entirely on Claude would be incomplete, so I decided to entrust draft generation and final review to Claude, while using a Local LLM to generate RAG for accurate evidence retrieval and to handle simple, repetitive tasks.
Gemma4:e4b
- Model Memory Limit: My MacBook Pro uses VRAM and RAM together, totaling 24GB. Since I run iOS and other tasks simultaneously, memory space is not abundant. If the model itself is heavy, context can be limited, and responses can be very slow or go off-topic.
- While LLM performance is certainly important, I believe harnessing is even more crucial for local LLMs that already have performance limitations.
- Speed: Aiming for fast speed by using e4b, which is designed for mobile/on-device use.
Thinking
- To do what I wanted, I needed to build some kind of harness, and I wondered if I could just use Claude-Code’s. I looked it up, and while some people had done it, the context would increase to a minimum of 40k. The moment it runs on the cloud, it deviates from my goal of trying to proceed as much as possible locally / and my LLM context window is only 32k.
- Looked for other harnessing tools.
- Efforts to minimize context.
Flow
- Step1 (Claude) : Generate PDF to Text Python Script
> **References**
> - `KISA` : Artificial Intelligence (AI) Security Guide (MSIT·KISA, 2025.12)
> - `NIS` : AI Security Guidebook (National Intelligence Service, 2025.12)
> - `FSI-AG` : Security Considerations for Authentication and Authorization Management in AI Agent Architectures (Financial Security Institute, 2025.09)
> - `FSI-GL` : Financial Sector AI Security Guidelines (Financial Security Institute, 2023.04)
> - `FSC` : Financial Sector AI Development and Utilization Guide (Financial Services Commission, 2022.08)
> - `AI기본법` : Framework Act on the Promotion of Artificial Intelligence and the Establishment of a Trust-Based Environment (2026.01.22)
> - `AI시행령` : Enforcement Decree of the Framework Act on Artificial Intelligence (2026.01.22)- Step2 (Claude) : Generate WIKI Structure
- Step3 (Claude) : Generate Prompt for Gemma e4b (summarize file by cutting to fit Gemma context length)
- Step4 (Gemma4) : Create WIKI (referencing reference txt file)
- Step5 (Claude): Draft security review items md file referencing WIKI data
- Step6 (Claude , Gemma4) : Final Markdown Table Review
- bge-m3:latest (local) — RAG Generation
- Generate RAG based on original text reference
- gemma4:e4b (local) — Heavy Repetitive Tasks
- Score md file based on WIKI and RAG (checking if it’s in the actual report, if it’s appropriate)
- Claude Sonnet 4.6 — RAG Design, Task Distribution to Gemma4:e4b, Final Report Review and Modification
- Final Markdown Quality Review (referencing Scoring using RAG)
- bge-m3:latest (local) — RAG Generation
Scoring Result) Two items were identified as partially met through scoring.
It’s uncertain if the items were well-chosen, but the reasons are quite logical.

Test2 Result (Review and Vulnerability Checklist)
- Supporting documents were well-found and written.
- However, for the vulnerability checklist, it seems necessary to further develop the methodology by actually performing the checks. I’d like to ask an AI practitioner at what point AI red teaming can be considered ‘good enough’…
Transclude of AI-보안성-심의-체크리스트.xlsx
Transclude of AI-vulnerability-checklist.xlsx
3) Find Vulnerabilities by Using AI
Find Vulnerabilities by Using AI
I wanted to summarize what I learned from the previous two tests (1 and 2) and apply it when proceeding with 3). It’s nothing groundbreaking, but here’s a summary of what I actually felt:
- Use Local LLMs only for tasks with very clear, simple, and repetitive objectives.
- Always use commercial AI for tasks requiring thought and reasoning.
- The easier the MCP integration, the better.
- RAG is also good when semantic search and original source verification are needed.
- I understand the need for AI Agent Flow tools (Flowise, n8n, etc.), but if debugging is important, simple calls are more convenient.
- HIL (Human In the Loop) is more necessary than I thought for me, who uses Claude Pro (Claude is dumber than expected).
- It’s difficult to find meaningful vulnerabilities by simply searching based on existing patch logs.
- Caveman skills save a lot of tokens.
- Initially, when analyzing an open-source project called Dify, I thought I could build existing source code as RAG and search with existing security diff (Before Code), but this was a thought I had without fully understanding AI. Contextual similarity does not imply code structure similarity.
- I conducted reviews of open-source projects like Dify, plane, n8n, and langflow, and after some adjustments, the current FLOW is as follows.
Problem Definition
- Target: Appealing open-source projects
- Success Criteria: Reproducible PoC + Vulnerability Report + CVE ID Acquisition
Flow
During each Phase, I record what was done within the phase folder. This helps prevent session interruptions or duplicate findings when searching for candidates.
-
Phase1. Environment Setup
- Environment setup is performed first.
- Although my FLOW design skills are lacking, I determined that understanding what kind of service the open-source project is, is necessary first.
- Set up with Docker / AWS, and if accounts exist, set them up with various permissions.
- Briefly grasp the open-source structure and write a readme about it.
-
Phase2. Vulnerability Information Discovery
- Existing Vulnerability Discovery
- Utilize GitHub API to check GitHub security advisories and security commit logs.
- Save vulnerabilities in the correct format ([CVE/GHSA ID] | [Type] | [Affected Module] | [Vulnerability Pattern] | [Remediation Method]).
- Count by type to set priorities.
- Identify areas likely to contain vulnerabilities.
- New features
- New files
- Attack surface grep (e.g., file/upload/request)
- Existing Vulnerability Discovery
-
Phase3. Information-Based Vulnerability Candidate Location Discovery + In-depth Analysis
- For parts found in Phase 2 (existing vulnerability priority order + new files from Phase 2):
- Extract code characteristics from CVEs and grep.
- semgrep
- Claude performs in-depth analysis of the vulnerability candidates found above.
- Verify where function input values originate.
- Create final vulnerability candidates.
- For parts found in Phase 2 (existing vulnerability priority order + new files from Phase 2):
-
Phase4. By Design Filter
- While searching for vulnerabilities, I found cases where Security.md stated that something was ‘Out of Scope’ or where maintainers explicitly stated ‘this is by design’ for issues raised.
- I reviewed Security.md and designs related to the identified vulnerability candidates.
-
Phase5. Vulnerability PoC
- Planned and obtained approval to actually proceed with PoC for the found vulnerability candidates.
- I was told to ask for human help if needed during further progress.
Reported 3 vulnerabilities, currently awaiting response… (06/09)
- If a response to the vulnerability report is received, I plan to proceed with detailed organization of that report.
What I learned from this project
-
When utilizing AI, harnessing is as crucial as performance.
- The purpose of using AI must be clearly defined.
- Output and input formats need to be fixed to achieve that purpose.
- Identify AI bottlenecks and control prompts or memory (constantly waiting for unnecessary things).
- It’s okay for things to take a bit longer, but if you can’t wait for work to progress, you need to review whether it’s actually a task worth waiting for every 5 minutes via a project md or a separate workflow, or proceed while logging.
- If the above problem definition is clear + there are enough tokens (financial resources) or computing power to run multiple agents, I think agentic engineering might be somewhat possible…
-
Issues arising from AI agentic engineering capabilities
- While authentication/authorization was certainly important, the increase in server-to-server communication raises the probability of vulnerabilities not only in client authentication but also in all end-to-end verification.
-
It’s necessary to consider methodologies for AI risk assessment (practical inspection methods), or the ability to design control over the values output by LLMs during design (harnessing).
-
Open-source analysis using AI is possible, but I am skeptical about using AI to find vulnerabilities in internal systems as a person in charge in the future. A huge number of vulnerability candidates will emerge, and only the person reviewing them will suffer. This project also took about 30 hours to verify meaningful vulnerabilities out of 10…
-
It seems that abilities such as performing Triage using AI, software architecture skills to structurally remove vulnerabilities, and managing complex authorization and authentication in Cloud/Container environments will become important.